"Read The Manual", he said.
And how I learnt about MySQL's PARTITION BY

I'm a Senior Software Engineer. With 10+ years working within tech teams, and 20+ years working with code, I develop across the stack, assisting with application design, maintenance, deployment and DevOps within the AWS Cloud.
After watching yet another Aaron Francis MySQL masterclass, I discovered a new function: PARTITION BY. What surprised me, is that it's not new.
PARTITION BY has been around since version MySQL 5.7! That's yonks ago!
I'll be the first to admit; that while MySQL's documentation is really helpful at times, most of the time, it's like an ocean, full of information, and I just need a drop of it to solve my problem. So I find myself reaching for blog posts, forums and videos to solve my issue.
And that's been a problem for me; instead of becoming comfortable with the docs, I reach for Google.
So why did I get RT*Med at work? Partly, because my colleagues are kind enough not to curse. But mainly, we were trying to find a use case, hidden in our data, not knowing if we had it or not for QA purposes. The issue was that I had no idea how to even write the query.
What use case was I looking for?
Company IP aside, imagine we had a table with data that could be grouped by a non-unique key, external_id. I wanted to find a grouping where the last row grouped by date had a nullable field but the row dated before did not. eg. I want it to pick out grouping by x and not grouping by y.
| external_id | Field A | Date |
| x | Some data | 2022-02-01 |
| x | More data | 2023-02-01 |
| x | NULL | 2024-02-01 |
| y | Some data | 2022-02-01 |
| y | NULL | 2023-02-01 |
| y | Final data | 2024-02-01 |
Now of course, GROUP BY with HAVING came to mind immediately because that's what I know. But that would merely find rows with a random mixture of nullable and non-nullable columns.
My naive approach at best was:
select
*,
sum(isnull(field_a)) as has_null,
sum(! isnull(field_a)) as has_not_null
from
my_table
group by
external_id
having
sum(isnull(field_a)) = 1
and sum(! isnull(field_a)) > 0;
This would have led to a useless answer:

A decade-plus of MySQL, shamefully, I didn't think this problem could be solved with MySQL alone. And yet, our database master (a.k.a, our CTO) solved the conundrum using it and his quick quip was (to paraphrase), "well, that's what happens when you RTM".
I managed to get this far as a developer while being squeamish about reading through documentation. It was his gain, and my loss in the end. I missed out on a fundamental piece of knowledge that would have helped create a simple MySQL query; MySQL Window Functions.
Discovering Window Function in MySQL
Now looking at MySQL's docs rather than Googling around, I found a surprisingly helpful example to copy. As I tend to learn by example, here's what MySQL shared:
SELECT
year, country, product, profit,
SUM(profit) OVER() AS total_profit,
SUM(profit) OVER(PARTITION BY country) AS country_profit
FROM sales
ORDER BY country, year, product, profit;

Now, I still don't fully understand how OVER works and it's a little hazy, but having a little think about things, and how to use PARTITION BY, I came up with this:
select
*
from
(
select
*,
-- Get total in group without using GROUP BY
count(external_id) over (
partition by external_id
) as total_in_group,
-- Ordered by row number
row_number() over(
partition by external_id
order by
external_id,
date
) as rownum
from
my_table
order by
external_id,
rownum
) t1
where total_in_group = rownum
and field_a is null
and total_in_group > 1;
Okay, so it looks a bit much, and there's probably a simpler way, but for a first pass, I'm pretty happy. And it was put together with some trial and error. So let's break it down a little.
For repetition, we have this data:
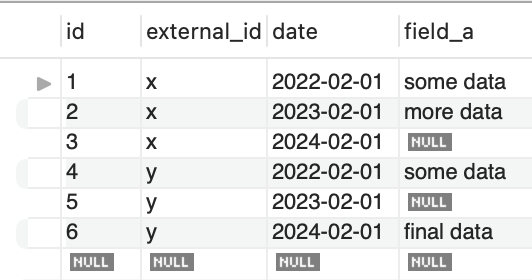
field_a is sometimes null, which is important to us.
Counting groups of data without GROUP BY
Now, what I want is to find the group of data, where the last dated field_a is null but the other fields are not null. So that means, I want to return group x.
To do this, I start by knowing the total number of items within a group but without using GROUP BY.
count(external_id) over (
partition by external_id
) as total_in_group,
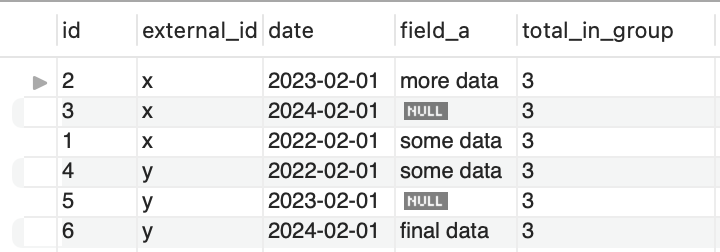
Ordering data within groups without GROUP BY
Next, I want to order the items in the group by date using the row_number() function.
row_number() over(
partition by external_id
order by
external_id,
date
) as rownum
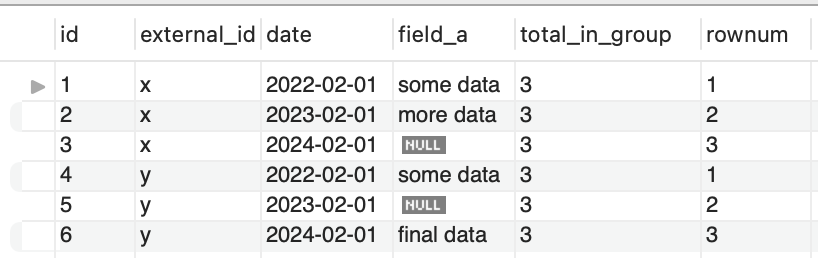
And now, it's like everything has fallen into place. All I need to do to find ID 3, is find where total_in_group = rownum and field_a IS NULL. That's it! 🎉. Throw in a subquery. Life is good.
Well, life may not be performant. I did do this on just 6 rows of data. At work, we were dealing with millions of rows, and Postgres, where isnull does not exist 😒. Anywho. Can't complain.
Although, it's still not quite correct. It would still work if the row before it contained a null field. But I was satisfied I was on the right track to solve the problem with a little more digging through the manual.
Knowing where to find solutions
I learn best by doing. I can't just read snippets and start writing code.
I need to understand what I'm reading in the context of building something tangible.
However, my faux pas is once I've grappled with the basics, I never look at the docs again. Where I've gone wrong, is I've read docs to solve a specific problem I had at the time.
Instead, Aaron's perspective is to read the docs to build a mental map of where to find solutions to problems we have in the future, not to understand everything in the docs today.
One example recently was at some point last year (2023) I came across an AWS article about Point in Time Recovery. I didn't even read it all.
While having a chat with our engineer, I brought up this article. As an alternative to another solution that worked in the past, it seemed both faster and simpler to implement! Now I couldn't tell him how it worked under the hood or how to implement it in Terraform or even via the GUI, purely knowing it was possible and where to find it was enough to make the suggestion!
Knowing where to find solutions, or that a solution exists, is a good reason to read the docs.
Learning to read the docs for leisure
Now, I just can't see myself, doing some pre-bed reading of Nodejs, albeit, for this exercise I did.
The recommendation of printing documentation and reading it through? I'm not sure about that. I love the visceral nature of physical books and writing by pen, but I also hate having unbounded paper everywhere.
Yet, searching for a solution under time pressure limits our creativity (as deeply explained in Hyperfocus by Chris Bailey). With a deadline, we narrow our focus to get the task done in the quickest time possible. So with a deadline in place...
Yes. I get things done.
No. It didn't look pretty.
Yes. I've produced many-a-bad solution while under a deadline, even if the thing works on the surface.
In comparison, sitting, leisurely reading, I'm just learning for fun.
Reading the docs for leisure is a very different way of absorbing information. It makes me think, the reason why many, including myself, shy away from reading the docs is because we read it when we need it, and so we don't have time to wade our way through the superfluous abundance of information. We need a solution, now!
Putting that to the test, I went back to read the docs just a little more, and I discovered that my query could be corrected.
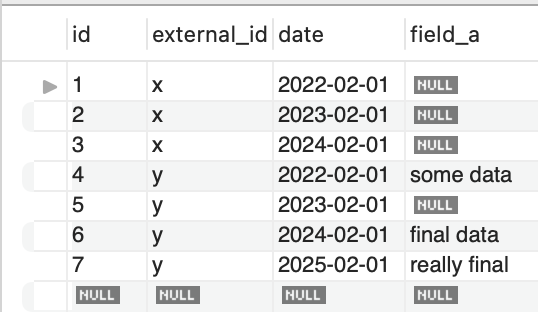
Remember, I want to select a group, where the last row in the group by date, has a nullable field, but the row before is not null.
Here's a more complete set, where we don't want group x or y, we want z.
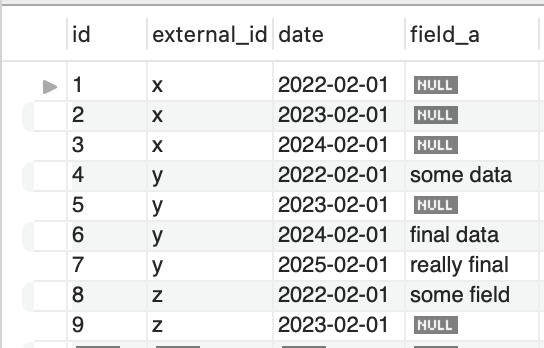
And voila 🥳.
select
*
from
(
select
*,
count(external_id) over (
partition by external_id
) as total_in_group,
row_number() over(
partition by external_id
order by
external_id,
date
) as rownum,
lead(isnull(field_a)) over(
partition by external_id
order by
external_id,
date
) as nullable
from
test.my_table
order by
external_id,
rownum
) t1
where
(total_in_group - 1) = rownum
and nullable = 1
and field_a is not null;
The addition was to use the LEAD function which gets the next record along. So I could then check if the next record after is nullable, and thus select ID 2. I could also find the second to last field using (total_in_group - 1) = rownum.
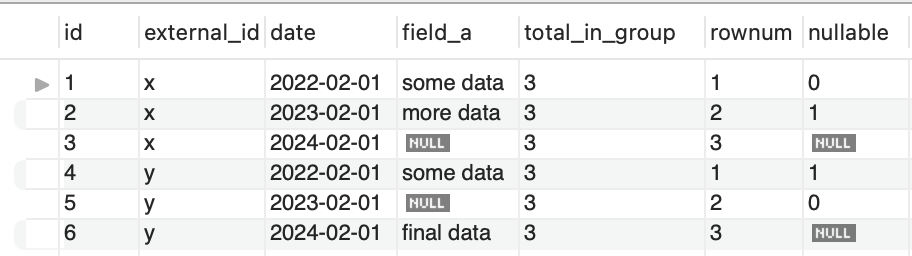
Yes, it's a little more complex, but it's great there are a few ways to solve this problem. And I've banked yet another MySQL function.
When reading the docs is bad!
So, reading the docs is great! Or is it?
Time is precious. And so we thank the developer who took the time to distil information in a format that could be read, over and over again to make his or her time scale rather than having to explain things constantly.
However, too much documentation might be a problem. In fact, in Fernando Villalba's article, I still can't believe the video he shared is genuine, but here's an example of verbose documentation gone wrong.
Fernando pointed out:
"If reading the manual is the only way for you to understand every functionality of your application, you have failed at design."
Too much documentation may be hiding bad design. Of course, with something like learning a programming language to solve a specific problem, it's rare for the language to be intuitive to just write it.
Intellisense helps.
Perhaps Copilot does too.
But outside of this, you have to read the manual. However, the tools we use, should be as intuitive as possible, so their function doesn't require having to read the manual to get started.
If they're not, we have an opportunity to help the maintainers:
improve their tools so they are intuitive to use. Too much documentation might be hiding bad design.
improve their docs by documenting contextually vs exhaustively, where we cannot make the tool more intuitive.
write external tutorials where we cannot improve the docs for whatever reason.
And what do we get out of it?
More skill[man/woman]ship.
More proficiency.
Known for mastery of a tool or technology which is great for our careers.
Better productivity.
Better design.
Better use of creativity.
And we can't read everything
Or can we?
Maybe if we just use a few tools instead of many, we can read all the docs, no problem.
But where I work, with so many tools and features being developed, I could spend all my time reading the docs, PRs, release notes and RFCs. I'd worry I'd get little to no work done.
So I need to be selective about what docs I read through.
What docs am I going to start reading?
I didn't want to do a MySQL tutorial, but quite the opposite. I was inspired by "Read the Docs Like a Book" article (another Aaron Francis special) which recommends becoming well acquainted with a set of documentation. The idea is that as you become more acquainted with your tools through the docs, you become a more skilled developer.
So, I decided I would "Read the Docs", and share notes on anything interesting. By interesting, it's mostly going to be things that are "new to me" or quirky. My current list to read contains:
Nodejs because I still don't understand Buffers and I'm surprised there's a native way to run tests. I also think I should try and master it in at least one language, seeing as I love it so much.
Nuxt because I love how it makes working with Vue easy but I couldn't tell you what a Composable is.
JSON Schema because I'm building Tin and it'll help with standardising data formats.
Rust because I have a goal to learn it this year.
C++ because I've been a developer long enough, I should eventually learn it, and it's a stretch goal.
K8s because I use it almost daily and still don't know how to use labels and metadata properly.
JQ because it's powerful and I love working on the CLI when testing APIs with HTTPie. HTTPie all day over Postman!
AWS because it is the Cloud!

